Interactive online version:
![]()
Getting Started with Equivariant Representations¶
Our general approach to equivariance is centered around the idea of representations, a prescription of how a group element acts on a given vector space.
Given a vector space \(V\) and a group \(G\), elements of the group \(g\in G\) can act on a vector \(v\in V\) by the representation matrix \(v\mapsto \rho(g)v\). The vector space \(V\) and the matrix \(\rho\) are often referred to interchangeably as the representation.
For example with the cyclic translation group \(\mathbb{Z}_4\), we implement a (faithful) base representation \(V\) which cyclicly translates the elements. Sampling an arbitrary transformation, we have
[1]:
from emlp.reps import V,sparsify_basis
from emlp.groups import Z,S,SO,O,O13,SO13,RubiksCube
import jax.numpy as jnp
import numpy as np
[2]:
G=Z(4)
rep = V(G)
v = np.random.randn(rep.size())
g = G.sample()
print(f"𝜌(g) =\n{rep.rho(g)}")
print(f"v = {v}")
print(f"𝜌(g)v = {rep.rho(g)@v:}")
𝜌(g) =
[[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]
[1. 0. 0. 0.]]
v = [ 0.00571103 0.1130348 0.43701055 -0.90977019]
𝜌(g)v = [ 0.1130348 0.43701056 -0.9097702 0.00571103]
The symmetric subspace of the representation is the space of solutions to the constraint \(\forall g\in G: \ \ \rho(g)v=v\). For any representation, you can get the basis \(Q \in \mathbb{R}^{n\times r}\) for this symmetric subspace with rep.equivariant_basis() and the matrix \(P=QQ^T\) which projects to this subspace with rep.equivariant_projector().
For example, we can find invariant vectors of the cyclic translation group \(\mathbb{Z}_n\) which is just the constant \(\vec{1}\) scaled to have unit norm.
[3]:
V(Z(5)).equivariant_basis()
[3]:
DeviceArray([[0.44721365],
[0.44721362],
[0.44721365],
[0.44721365],
[0.44721365]], dtype=float32)
The Representation Type System¶
Each implemented group comes with a faithful ‘base’ representation \(V\). Because faithful representations are one-to-one, we can build any representation by transforming this base representation.
We provide several operators to transform and construct representations in different ways built and later go on to show how to do this more generally. In our type system, representations can be combined with the direct sum \(\rho_a \oplus\rho_b\) operator, the tensor product \(\rho_a\otimes\rho_b\), the dual \(\rho^*\) and these operators are implemented as the python operators +, *, and .T.
[4]:
V+V, V*V, V.T
[4]:
((V+V), V⊗V, V*)
We can combine and use these operators interchangeably:
[5]:
(V+V.T)*(V*V.T+V)
[5]:
(V+V*)⊗(V⊗V*+V)
We use the shorthand \(cV\) to mean \(V\oplus V\oplus...\oplus V\) and \(V^c = V\otimes V\otimes...\otimes V\). Note that this differs from the common notation where \(V^c\) denotes the cartesian products the set (like with \(\mathbb{R}^c\)) which would be the same as \(cV\) in this notation. Being more formal we could distinguish the two by denoting \(V^{\otimes c}=V\otimes V\otimes...\otimes V\) but to stay consistent with the python interface, we will not.
[6]:
5*V*2
[6]:
(V+V+V+V+V+V+V+V+V+V)
[7]:
2*V**3
[7]:
(V⊗V⊗V+V⊗V⊗V)
When a particular symmetry group is specified, the representation can be collapsed down to a more compact form:
[8]:
G=O(4)
2*V(G)**3
[8]:
2V³
[9]:
(2*V**3)(G)
[9]:
2V³
Although for groups like the Lorentz group \(SO(1,3)\) with non orthogonal representations, a distinction needs to be made between the representation and it’s dual. In both cases the representation is converted down to a canonical form (but the ordering you gave is preserved as a permutation).
[10]:
V(SO(3)).T+V(SO(3))
[10]:
2V
[11]:
V(SO13()).T+V(SO13())
[11]:
V+V*
Linear maps from \(V_1\rightarrow V_2\) have the type \(V_2\otimes V_1^*\). The V>>W is shorthand for W*V.T and produces linear maps from V to W.
Imposing (cyclic) Translation Equivariance \(G=\mathbb{Z}_n\) on linear maps \(V\rightarrow V\) yields circular convolutions (circulant matrices) which can be expressed as a linear combination of \(n\) basis elements of size \(n\times n\).
Exploring and Visualizing Equivariant Bases¶
[12]:
G = Z(6)
repin = V(G)
repout = V(G)
conv_basis = (repin>>repout).equivariant_basis()
print(f"Conv basis has shape {conv_basis.shape}")
Conv basis has shape (36, 6)
While we provide an orthogonal basis, these bases are not always easy to make sense of as an array of numbers (any rotation of an orthogonal basis is still an orthogonal basis)
[13]:
conv_basis[:,0]
[13]:
DeviceArray([-0.00200776, -0.25157794, 0.31927773, 0.0072209 ,
-0.03698727, 0.00357165, 0.00357159, -0.00200781,
-0.25157797, 0.31927782, 0.00722108, -0.03698722,
-0.03698726, 0.00357183, -0.00200774, -0.2515779 ,
0.31927767, 0.00722109, 0.00722104, -0.03698728,
0.00357171, -0.00200778, -0.25157782, 0.31927767,
0.3192777 , 0.00722104, -0.03698733, 0.00357174,
-0.00200774, -0.2515779 , -0.25157785, 0.3192777 ,
0.00722107, -0.03698731, 0.00357177, -0.0020077 ], dtype=float32)
To more easily visualize the result, we can define the following function which projects a random vector and then plots components with the same values as different colors, arranged in a desired shape.
[14]:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
def vis_basis(basis,shape,cluster=True):
Q=basis@jnp.eye(basis.shape[-1]) # convert to a dense matrix if necessary
v = np.random.randn(Q.shape[0]) # sample random vector
v = Q@(Q.T@v) # project onto equivariant subspace
if cluster: # cluster nearby values for better color separation in plot
v = KMeans(n_clusters=Q.shape[-1]).fit(v.reshape(-1,1)).labels_
plt.imshow(v.reshape(shape))
plt.axis('off')
def vis(repin,repout,cluster=True):
Q = (repin>>repout).equivariant_basis() # compute the equivariant basis
vis_basis(Q,(repout.size(),repin.size()),cluster) # visualize it
Our convolutional basis is the familiar (circulant) convolution matrix.
[15]:
vis_basis(conv_basis,(repin.size(),repout.size()))
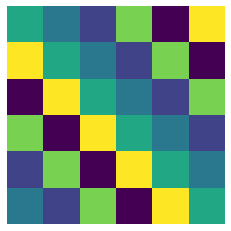
2D translation equivariange \(G=\mathbb{Z}_n\times \mathbb{Z}_n\) yields 2D convolutions (bicurculant matrices)
[16]:
G = Z(3)*Z(4) #[Not recommended way of building product groups, there is a faster way shown in section 5]
repin = V(G)
repout = V(G)
vis(repin,repout)

How about the permutation group \(G=S_n\), where the vector space \(V\) represents a set of elements? In deep sets it was shown there are only two basis elements for equivariant linear maps \(V\rightarrow V\).
[17]:
repin = V(S(6))
repout = V(S(6))
vis(repin,repout)

What about graphs, which are composed both of sets as well as adjacency matrices or graph laplacians? These matrices are examples of objects from \(V\otimes V\) with \(G=S_n\), and in Invariant and Equivariant Graph Networks () it was shown through a challenging proof that there are at most 15 basis elements which were derived analytically. We can solve for them here:
[18]:
repin = V(S(6))**2
repout = V(S(6))**2
vis(repin,repout)
print(f"Basis matrix of shape {(repin>>repout).equivariant_basis().shape}")
(1296, 15)

How about the continuous \(2\)D rotation group \(SO(3)\)? It’s well known that the only equivariant object for the vector space \(V^{\otimes 3}\) is the Levi-Civita symbol \(\epsilon_{ijk}\). Since the values are both \(0\), positive, and negative (leading to more than Q.shape[-1] clusters) we disable the clustering.
[19]:
W = V(SO(3))
repin = W**2
repout = W
Q = (repin>>repout).equivariant_basis()
print(f"Basis matrix of shape {Q.shape}")
vis(repin,repout,cluster=False)
Basis matrix of shape (27, 1)
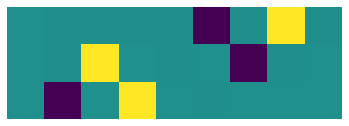
[20]:
print(sparsify_basis(Q).reshape(3,3,3))
[[[ 0. 0. 0.]
[ 0. 0. 1.]
[ 0. -1. 0.]]
[[ 0. 0. -1.]
[ 0. 0. 0.]
[ 1. 0. 0.]]
[[ 0. 1. 0.]
[-1. 0. 0.]
[ 0. 0. 0.]]]
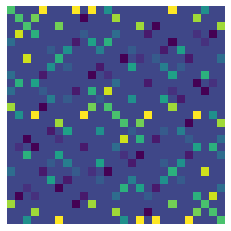
We can also solve for very high dimensional representations which we automatically switch to using the automated iterative Krylov subspace method
[21]:
vis(W**3,W**3)
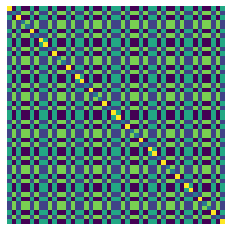
[22]:
vis(W**5,W**3)

[23]:
vis(V(RubiksCube()),V(RubiksCube()))
Composite Representations and Lazy Matrices¶
How about maps from graphs to sets? Lets say a graph consists of one node feature and one edge feature which can be represented with the \(\oplus\) operator.
[24]:
W = V(S(6))
repin = W+W**2 # (one set feature and one edge feature)
repout = W # (one set feature)
vis(repin,repout)
print(f"Basis matrix of shape {(repin>>repout).equivariant_basis().shape}")
(252, 7)

Representations that have many copies or multiplicity of a given representation type, such as for the many channels in a neural network, are simply examples of the \(\oplus\) operator (+ in python). The rep.equivariant_basis() and rep.equivariant_projector() can return lazy matrices \(Q\) and \(P=QQ^T\) when the representations are composite (or when the representation is specified lazily). These Lazy matrices are modeled after scipy
LinearOperators. By exploiting structure in the matrices via fast matrix vector multiplies (MVMs), it can be possible to work with extremely large matrices.
For example with a more realistically sized layer with 100 global constants, 100 set feature channels, and 20 edge feature channels (\(100V^0+100V^1+20V^2\)) we have
[25]:
W = V(S(6))
repin = 100*W**0 + 100*W+20*W**2
repout = repin
rep_map = repin>>repout
print(f"{rep_map}, of size {rep_map.size()}")
Q = rep_map.equivariant_basis()
print(f"Basis matrix of shape {Q.shape}")
10000V⁰+20000V+14000V²+4000V³+400V⁴, of size 2016400
Basis matrix of shape (2016400, 84000)
Unfortunately the larger matrices are harder to visualize as for the matrix above we need 84000 different colors! We are happy to field suggestions for visualizing very large bases.
[26]:
P =rep_map.equivariant_projector()
v = np.random.randn(P.shape[-1])
v = P@v
plt.imshow(v.reshape(repout.size(),repin.size()))
plt.axis('off');
[26]:
(-0.5, 1419.5, 1419.5, -0.5)

[ ]: